To appear in: P.Grzybek (ed.). Studies on Length Regularities
in Linguistics. – Graz: Graz Univ. Press, 2003.
Explaining Basic Menzerathian Regularity:
Dependence of Affixes' Length on the Ordinal Number
of their Positions within Words
Anatoliy A. Polikarpov
Moscow Lomonosov State University
Faculty of Philology
Laboratory for General and Computational Lexicology and
Lexicography
Home address: Kv. 204, dom 9-1 proezd Karamzina, Moscow 117463
Russia
office phone (and fax): +7 (095) 939-31-78
home phone: +7 (095) 422-41-95
e-mail: polikarp@philol.msu.ru
Summary
In the submitted paper, first, there are present some basic points of an evolutionary model for understanding the logic of word-formational process responsible for arising of general word/morpheme length regularities and, second, some Russian language data (50787 Russian root and affixed words) for the initial testing of the model. Main attention in this work is paid to the most fundamental dependence of this kind - negative correlation of morphemes' length with the unified scale of morphemes' positional features within their word-forms. Author has arrived at the conclusion that this can be best of all formalised by a logarithmic dependence of the form as it follows:
y = -a*ln(x+c) + b, where y - average length of affixes being in a position of x ordinal affixal number in their word-forms; a - coefficient of proportionality; b - average length of affixes in the initial (-3rd) position within word-forms present in the analysed dictionary; c - coefficient for converting of a negative-positive scale into a pure positive one.
Empirically revealed oscillative character of general dependence of suffixes' length on their positional numbers is also explained.
Observations on specific features of menzerathian regularities for different kinds of morphemes (roots, prefixes, suffixes) and for all kinds of morphemes together in words of different ages provide further deeper insight into the “Menzerath’s Law” phenomenon.
1. Unexplained state of the “Menzerath’s Law” phenomenon.
“Menzerath’s Law” is usually considered as one of the most fundamental regularities in Human Language organization. In its historically initial form it described the empirically obtained regularity of negative correlation of the average length of word syllables (measured in letters or phonemes) with length of words (measured by number of contained in them syllables) [Menzerath, 1954]. Later on this "law" was expanded for describing regularities of units on various levels of language organization (morphemic, syntactic, textual, etc.) and even for describing other semiotic, biologic, etc. phenomena. In the most general formulating Menzerathian regularity was defined as follows: the longer some “construct” (the whole) the shorter should be its “components” (parts) [Altmann, Schwibbe, 1989; Hrebicek, 1995]. Nevertheless, the "Law" wasn’t satisfactory founded theoretically not in linguistics, nor in any other corresponding sciences. The most interesting attempts of the "Law" theoretical study are present by works [Altmann, 1980; Altmann, Schwibbe, 1989; Koehler, 1989; Fenk and Fenk-Oszlon, 1993; Hrebicek, 1995].
Moreover, there is not so much done in the primary field of empirical study of menzerathian regularities - in linguistics. The most considerable contribution to multilevel empirical study of the phenomenon in linguistics was made in the work [Hrebicek, 1995].
What is the most striking, the menzerathian regularities were not almost studied empirically on the basic level of any national variety of Human Language organization, level of its morphemic units. Until now we have only sporadic word/morphemic studies of only three languages - German [Gerlach, 1982], Turkish [Hrebicek, 1995] and Russian [Polikarpov, 2000; 2000a]. Meanwhile, it is natural to expect that regularities of units from some basic level of Human Language organization should determine to some significant extent regularities of any other upper lying levels of it. So, the whole building of linguistic theory (including quantitatively oriented length theory of syntactic and suprasyntactic units) without solid basis of explained regularities for the most elementary, ultimate sign units of a language - morphemes - cannot be built in principle. So, there is a vital necessity, first, for considering theoretical foundations of possible onthological mechanism leading to the arising of language units' length regularities. Second, obviously, it should be begun from the elementary – morphemic – level of language system. It is necessary to gather and analyze extensive and multiaspectually characterized data on morfemic structures of words in various languages.
This paper is a step on the road of building a theory of word/morpheme relationship and widening empirical basis for testing a model of word/morphemes length regularities using Russian language data.
2. Evolutionary model as a basis for revealing structure of word-formational regularities.
2.1. Directionality of word-formational process as a derivative of directionality of basic semantic drift. According to the Model of sign life cycle [Polikarpov, 1993; 1998; 2000; 2000a; 2000b; 2001; 2001a; Khmelev, Polikarpov, 2000] it is natural to expect that the most probable (statistically dominant) direction for the categorial order within the branches of any nest of derivationally (word-formationally) connected words will be the movement from word-bases of some relatively concrete, objectively oriented categorial semantics towards their derivatives of gradually more abstract, subjectively oriented and functional quality, i.e. towards words of gradually more grammatical parts of speech. So, there should be a tendency to begin a word-formational tree mainly from nouns, to continue it usually by adjectives, verbs, adverbs, pronouns, etc., and to end it in typical case by words of pure syntactic (functional) quality like conjunctions and prepositions. This general direction of words' categorial development within any nest is predetermined most basically by two fundamental semantic processes acting together in the same direction in history of any word (as well as in history of any other linguistic sign): (1) by the inescapable gradual drift of any word's meaning quality in time, during each speech act, mainly into the direction of its gradually greater abstractness and subjectivity, (2) by the predominant relative change of new word meanings into the direction of their greater abstractness as compared to maternal meanings. Correspondingly, this is a direction of the quality drift of the integral semantics of any word in time.
According to the principle of necessity for close correspondence between lexical and categorial semantics of words [Polikarpov, 1998], becoming more abstract lexical semantics “seeks” corresponding more abstract categorial (part-of-speech) form which is more organic to it and “finds” it in acts of word-formation, production of derivatives with greater concord between lexical and categorial semantics than it is specific at the moment for word-bases.
Production of derivatives of more grammatic word categories at each next step of word formation is reached usually by means of adding relatively more abstract, more grammatic suffixes to corresponding word-bases. As time goes, a former derived "new word" becomes semantically more abstract than it was initially. Therefore it looses semantic-grammatic concord obtained initially and correspondingly tends to give birth to a new, categorially else more abstract derivative than it is now itself. Repeating (but gradually retarded in time in their intencity) acts of word-formation lead eventually at some nests to forming of pure grammar (functional) words.
2.2. Prefixes versus suffixes: principle difference in function. Prefixes added step by step to the left of a root during word-formational process, on the contrary, are usually relatively more semantically specific, concrete than those prefixes which were put into the word-form before them. This significant difference in semantic quality direction of relative changes between prefixes and suffixes within their growing chains is explained by the principle difference in function of these two different kinds of affixes. A function of prefixes is not to establish new grammar categories of words (as it is specific for suffixes), but to vary aspectually already established (with the help of suffixes) categories by way of “multiplying” them by different aspectual meanings of prefixes.
2.3. Correlation of categorial, age, frequency and length ordering of morphemes within word-forms with their positional ordering. The above mentioned fact of functional difference between prefixes and suffixes predetermines significant difference (even opposition) in the direction of the positional dependence of semantic quality, frequency and length of suffixes and prefixes in any word-form. More grammatic affixes usually are the result of some longer history in language. So, they should be more aged, more frequent than less grammatical ones. Greater frequency of use of more grammatic affixes determines their corresponding shortening. Growing in two opposite directions (to the right and to the left of a root) chains of affixes correspondingly change their age, grammar, frequency and length features also in two opposite directions.
The most remarkable consequences of the mentioned processes are concerned with the specific categorial, age, frequency and length ordering of different kinds of morphemes within any word-form. They are as follows:
- suffixal units which are more distant to their root (are at more remote position to it) should be proportionally more grammatical, more frequent, and, finally, shorter than less distant ones;
- prefixal units which are more distant to their root, on the contrary, should be proportionally less grammatical, less frequent, and, finally, longer than less distant ones;
- while being gradually in time “packed” by growing number of new affixes (cumulated in word-forms during word-formational process) roots, as well as affixes put into word-forms before, should become more abstract, more frequent in use and therefore should gradually become shorter.
So, the whole picture of morphemes’ length changes during the process of growing number of all morphemes step by step added to word-bases is not homogeneous. It consists of, at least, three components which should be discriminated. Prefixes and suffixes follow two different, even opposite tendencies of their functional and structural dependenceon the positional number of their placing. Roots should follow one else, specific law of their length changes as function of the growth of affixal chains within word-forms containing that or another root.
In sum, our model predicts negative correlation of suffixes’ length and positive correlation of prefixes' length on their growing positional number within their word-forms. Correspondingly, we predict positive correlation of prefixes’ length on their overall quantity, and negative – of suffixes length on their overall quantity within word-forms. So, dealing with the dependence of average affixes' length on overall number of affixes (suffixes and prefixes together) we, seemingly, do not obtain some homogeneous dependence. This fact wasn’t mentioned still in any of menzerathian studies, because of too abstract approach to the problem in many of them, not taking into account real basic mechanisms of the word-formational process.
Specific role and specific dynamics of roots within lengthening word-forms also was not noticed yet.
Therefore positional numbers of prefixes and suffixes in this case are of primary interest to those who try to model the process. Positional numbers are oriented to a root as a center of word-formational process and a zero point in word-formational static structure. Positional features constitute some basic system of coordinates for the object under study which should be taken into account in the very beginning of its study. Overall number of morphemes in a word (which is usually taken as the main determinant of "part/whole" length relations in a word) is not more than some combined (mixed) parameter. Exact form of this parameter’s influence on the average morphemes' length should be still carefully considered, analytically derived from taking into account three more fundamental dependencies. They are positional dependencies separately acting for suffixes and prefixes' length, and menzerathian-like dependence for roots' length (which depends on the maximum number of those positions).
If the growth of number of prefixes in any word-form is correlated with the growth of number of suffixes and if the degree of corresponding changes for the average length of suffixes and prefixes (while growth of length of their chains) is correlated, it will give an opportunity to come to the more reasonable conclusion on the really more sophisticated dependence of affixes' length on the overall number of affixes and, correspondingly, on the overall number of morphemes in a word-form.
Even if it is so, it still should be analytically integrated with the corresponding dependence of roots' length on growing length of chains of affixes (and morphemes, on the whole) within some complex equation of menzerathian type.
All in all, the so-called ”Menzerath's Law” for word/morphemic relations is a mixed result of acting of three different, more elementary laws (differently affecting prefixal, root, and suffixal length), which should be considered one by one for arriving further, possibly, to the eventual decision about their integration into some complex law.
Even more fundamental for understanding the phenomenon is studying of the length/age relationship, as it follows from the Model of sign’s life cycle. Data on these fundamental features are present below.
3. Source of data.
In the submitted paper those data were analysed which concern morphemic structures of root and affixally derived Russian words (50,747 different words) from the whole database “Chronological Morphemic and Word-Formational Dictionary of Russian Language” (CMWDRL) containing, on the whole, more than 180,000 words. The DB has been prepared at the Laboratory for General and Computational Lexicology and Lexicography of Moscow State Lomonosov University. The data from this dictionary has been characterised and initially analyzed in [Polikarpov, Bogdanov, Kryukova, 1998; Polikarpov, 2000; 2000a]. The data were present and analyzed with the help of Access97 and Excell97 DB shells.
4. Possible mathematical form for the law of affixes’ length dependence on their positional number.
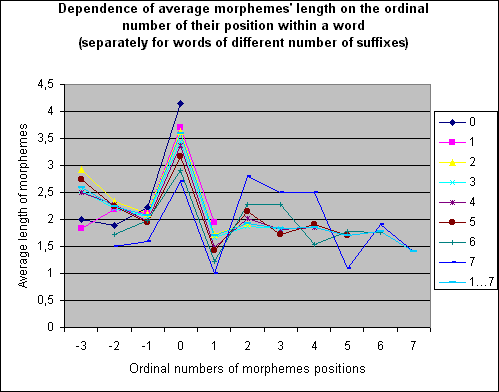
4.1. From 3-factor to 2-factor model. Our experimental investigation of the material from the above-mentioned Dictionary CMWDRL shows that this three-factor model of morphemes’ length dependence can be simplified, reduced to two-factor one, if we take into account that prefixal and suffixal tendencies of changes are really correlated and can be considered as components of the integral construction, as different, but closely correlated results of some unified process. On this basis it is possible to establish a unified distant scale for prefixes and suffixes, when a root “center” is symbolised by a zero ordinal number of its position, while suffixes - by increasing positive numbers and prefixes – by increasing (in absolute value) negative ones. It is possible to see (Table 1 and Figures 1, 2 below) that this statement is valid, except for oscillative nature of suffixes’ positional dynamics (which is discussed below, in the section 4.4. Yet there is a necessity for explaining the fact of close correlation between them by further deepening into the quality nature of word-formational process.
Table 1. Dependence of Lengths of Morphemes of Different Type on the Ordinal Number of their Positions in a Word (for words with different number of suffixes separately)
| Number of suffixes in words | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 1-7 |
| Number of words having different number of suffixes in them | 2820 | 5408 | 22755 | 15526 | 3663 | 535 | 70 | 10 | 50787 |
| Positions of morphemes in words | Average letter length of morphemes | ||||||||
| -3 | 2,000 | 1,833 | 2,926 | 2,545 | 2,500 | 2,750 | - | - | 2,597 |
| -2 | 1,886 | 2,180 | 2,326 | 2,199 | 2,283 | 2,250 | 1,727 | 1,500 | 2,249 |
| -1 | 2,221 | 2,116 | 2,105 | 2,047 | 1,971 | 1,937 | 1,981 | 1,600 | 2,080 |
| 0 | 4,146 | 3,705 | 3,632 | 3,446 | 3,367 | 3,172 | 2,914 | 2,700 | 3,586 |
| 1 | - | 1,946 | 1,715 | 1,659 | 1,476 | 1,424 | 1,229 | 1,000 | 1,700 |
| 2 | - | - | 1,931 | 1,870 | 2,027 | 2,144 | 2,271 | 2,800 | 1,921 |
| 3 | - | - | - | 1,839 | 1,806 | 1,721 | 2,271 | 2,500 | 1,831 |
| 4 | - | - | - | - | 1,846 | 1,905 | 1,543 | 2,500 | 1,850 |
| 5 | - | - | - | - | - | 1,701 | 1,771 | 1,100 | 1,699 |
| 6 | - | - | - | - | - | - | 1,757 | 1,900 | 1,775 |
| 7 | - | - | - | - | - | - | - | 1,400 | 1,400 |
| average letter length of all morphemes | 3,474 | 2,695 | 2,369 | 2,181 | 2,092 | 2,008 | 1,962 | 1,926 | 2,309 |
| average letter length of all prefixes | 2,193 | 2,119 | 2,124 | 2,059 | 2,002 | 1,977 | 1,938 | 1,571 | 2,094 |
| average letter length of all suffixes | - | 1,700 | 1,921 | 1,831 | 1,850 | 1,699 | 1,775 | 1,400 | 1,810 |
Figure 1.
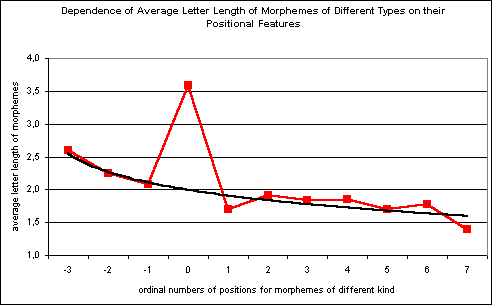
Figure 2.
4.2. An attemt of revealing the general form for the positional dependence of affixes' length. Basing on the above stated theoretical positions we have considered different possible mathematical forms of the positional effect of affixes placement within word-forms. We have arrived at the conclusion that this can be best of all formalised by a logarithmic dependence:
y = -a*ln(x+c) + b, (1)
where
y - average length of affixes being in some numbered
position in their word-forms;
x – positional number of affixes;
a - coefficient of proportionality;
b - average length of affixes in the initial (-3rd)
position within word-forms present in the analysed dictionary;
c - coefficient for converting of a negative-positive
scale into a pure positive one (c is here maximum ordinal number of
prefixes plus one in words of any given dictionary).
4.3. Parameters of the positional dependence for length of affixes in Russian words from CMWDRL. Results obtained on the basis of analysis of the above-mentioned dictionary of Russian words CMWDRL show clear validity of the theoretically derived dependence. Besides, we revealed significant oscillations of the dependence (see below point 4.4) and stable variations of the regularity depending on various ages and various categorial form of words, and on categorial status of morphemes (for roots of words as opposed to affixes), etc.
The exact values for a and b values in the proposed positional dependence of affixes' length are present as follows:
a = -0,3953
b = 2,5473
c = 4.
The equation for the dependence of Russian morphemes' average length on their posional numbers is as follows:
y = -0,3953ln(x+4) + 2,5473. (2).
Parameters of the equation have been calculated on the basis of data present in Table 1. Length of morphemes is measured by the number of letters in them. According to specific features of Russian alphabet there is a very close (almost one-to-one) correspondence between Rusian letters and phonemes. So, it is possible to use both kinds of units without noticeable difference.
4.4. Oscillations in the dependence of suffixes' length on their positional features. Analysing data present at Table 1 and Figures 1 and 2 one can easily notice not only the general fact of correlation between positional and length features of suffixes, but also a minor fact of oscillations, rythmic local deviations of average suffixes' length from the theoretically drawn general tendency at each of odd number of derivational steps. The fact of oscillation of word length features (as well as frequency and other features) while considering their dependences on some other language features was already noticed (see, for instance, [Koehler, 1986]). But, seemingly, it was not properly evaluated, was not explained as one of remarkable system necessities. Proper evaluation for the oscillation phenomenon can be given only within the above present evolutionary model of word-formational process. We suppose that small rythmic deviations of this kind reflect some basic rythm of word-formational process.
For modeling this phenomenon it is enough to make two assumptions. First (the main, already explained above): greater probability to produce at each next step a new derivative as some more categorially abstract one than a derivative at each previous step. Second: acts of production of more and less categorially abstract derivatives should take turns for the whole chain of derivatives in any nest.
Despite of the possibly seeming contradiction between two statements present above there is no real inconsistency. First assumption concerns only summarised picture for the whole chain of all derivatives, on the average, without taking into account their closer pair relations. Second assumption, on the contrary, take into account only relations of contiguous derivatives in succession of Markovian-like pairs of them. Real interaction of two tendencies is present in the form of modulations of the general tendency (for diminishing affixes' length from left to right within a word) by some rythmic, autocorrelative "plus" and "minus" deviations of real length values from those values which are determined by the main tendency.
It is still uncertain, whether oscillations concern also prefixes or not.
The backward tendency within derivational pairs (like the derivational movement from an adjective back to a noun) is explained by the necessity to produce those derivatives which could be used for expressing almost the same meanings, but in greater variety of syntactic conditions than was possible for their immediate derivational predecessor. For instance, substantivation of the form of expressing various static and dynamic features of objects (expressed usually by adjectives and verbs) is one of means for use the substantivised name of a feature (a feature itself is characterising some set of objects in Nature) in the most syntactically open and flexible - object - position. This syntactic position provides some additional opportunities for the specification (if necessary) of the denoted feature by the possible additional use of attributes and predicates of it and object (circumstantual) determinants around it.
If we take for granted that in majority of cases a word of the initial, zero degree of derivation within a word-formational nest is present by a noun (usually having physical object reference and not having any affixal "clothes", i.e. being present by a pure root), it means that in the beginning of suffixation (at suffixal position №1, just after a root) there can be the movement mainly into the direction of noticeably relative greater categorial abstractness with use of some relatively shorter suffix. Next, second suffixation step, can be in either of two directions - (1) to the greater and (2) to the lower categorial abstractness. But in majority of cases it is realised into the second - categorially concreticising direction and, corespondingly, in increasing of length of a suffix used at the step. It is because of the strong negative correlation between quality of contiguous derivation steps within any nest. But this substantivising "revenge" is preparing some additional abstractivising opportunities for those words which have undergone substantivising at the previous step. So, the third step should be, according to the second tendency of negative correlation between the the direction of quality changes for contiguous derivation steps, again mainly into the direction of greater categorial abstractness of derivatives than that of their word-bases and, correspondingly, into the direction of shortening, on the average, suffixes used on this step. This, in its turn, gives additional opportunities for the next step to substantivisation of derivatives (as compared to wordbases), to relative categorial and semantic specification of used here suffixes and, correspondingly, to relative growth of their length. The fourth step will repeat the relative logic of the second one, etc.
All in all, there should be a picture of some general process of average suffixes' (and prefixes) shortening while moving along affixes’ positional scale. Besides, the process is modulated by oscillations, rythmic (regularly repeating) plus and minus deviations within, at least, suffixal zone. Seemingly, prefixal zone is influenced only by the general tendency, without oscillations. But the last statement still needs additional theoretical and empirical support.
5. Realisation of menzerathian regularities separately for roots, prefixes and suffixes in words having different number of suffixes.
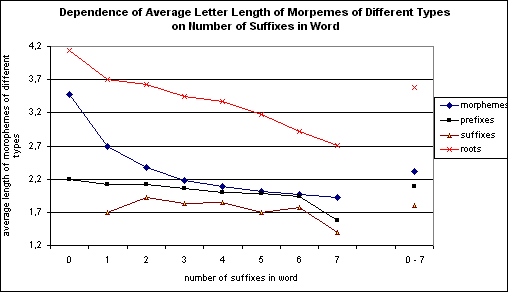
For deeper understanding the process, for more differentiated analysis of morphemes of different quality we have obtained a series of projections of roots', prefixes' and suffixes' length dependence on length features of words. Here we present dependence of length features of the above-mentioned kinds of morphemes units on number of suffixes in words (see Figure 3). We suppose that this menzeratian regularity is the closest among others to the most fundamental - positional - length dependence regularity for affixes of words. That is why we use it for the analysis first of all.
Initial considering show significant difference of the units in the dynamics of their dependence on number of suffixes in words. The most important to note, first, that roots are opposed to affixes on the whole and, second, that prefixes during all diapazone of word lengths are, on the average, longer than suffixes. This demonstrates the greatest degree of lexicality of roots, lesser degree - of prefixes and the least degree - of suffixes.
Exact form of this dependence needs further study. Now it is possible, at least, to say that the dependence is less homogeneous for roots than for any other kind of morphemes (yet with noting that chains of suffixes are influenced by the factor of oscillations).
Figure 3.
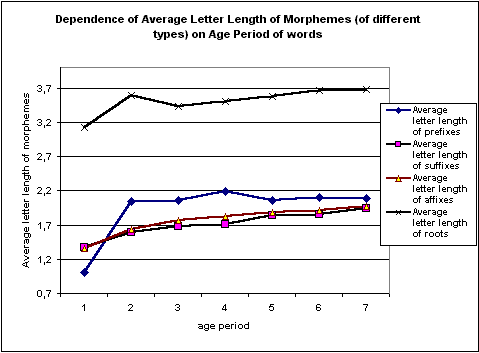
6. Menzerathian regularity for morphemes of words of different age.
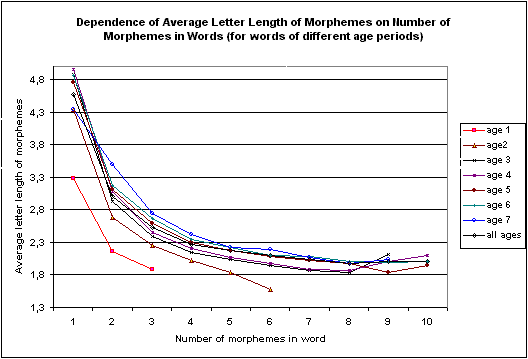
According to our data from CMWDRL words of the same length (i.e. of the same number of morphemes in them) proportionally to the decline of their age are built with the use of gradually longer morphemes – see Figures 4 and 5.
There are 7 grades of ages - from the 1st, most ancient words of Indo-European (and older) origin, to gradually younger words of the 2nd (Common Slavic) period, 3rd (Old Russian), 4th (15-17th centuries of origin), 5th (18th century), 6th (19th century) up to 7th age period (words of the origin in 20th century).
This, presumably, demonstrates that, on the average, younger (and therefore - less semantically abstract and less grammatical) words are usully built by relatively younger (and, correspondingly, by less grammatical, less frequent, and, therefore - longer) morphemes than, on the average, older words. This shows the necessity to discriminate between the influence of the length of words and their age on the average length of affixes. Presumably, length and age of words are correlated, but separately acting factors in the complex process of affixes' length formation.
Possibly, it shows the necessity to develop further a formal apparatus of modelling positional and menzerathian-like dependences which would include not only
positional (or or overall length) features of words, but also their age properties for taking into account regular age modifications of the considered dependences.
Figure 4.
One else projection of word age -morphemic length relations is present by the figure 5 below. It shows even more clear the fact of the dependence of the average length of morphemes of any kind on age of words containing those morphemes.
Figure 5.
7. Conclusion.
A revealed (predicted and prooven) in our study phenomenon of the average affixes’ length negative dependence (possibly, logarithmic) on the unified ordinal number of morphemes’ position within a word, in our opinion, is a result of functional determination of words and morphemes structural features.
For deeper understanding observed features it is necessary to take also into account age features of words and morphemes.
Oscillative phenomenon for further studies of menzeratian regularities is of primary importance. As it was shown, general tendency for relative greater categorial abstractness of derivatives of each next step of word-formational chain is modified by oscillations as a result of collaboration of the main tendency (of production of new word of relatively more abstract category, for instance, in the course of derivational movement from nouns to adjecives: friend - friendly), with a minor tendency of negative correlation between acts of derivaion in two opposite directions (abstractivisation and concretisation) within each word-formational chain. So, if at the zero step of the process we usually have almost pure concrete word category (semanically objective nouns), next (1st) step of derivation should result in overwhelming majority of non-nouns produced. Second step, according to the mentioned-above negative correlation of steps, should again restore to some degree categorial quality lost during previous step of derivation (like derivation of friendliness from friendly). Nevertheless, this back and forward movements are realised within more general tendency to the eventual relative abstractivisation of word (and suffix) categories. Seemingly, general tendency is present by a block consisting of every next pair of derivational steps. Each next block, on the average contains more abstract word category and, correspondingly, a shorter suffix, than each previous block. Oscillations in this case may be considered as inner processes inside each such block.
The so-called ”Menzerath's Law” for word/morphemic relations is a mixed result of acting of three different, more elementary, local laws (differently affecting prefixal, root, and suffixal length), which can be integrated into some more complex dependence only taking into accounteach of them one by one. Here we undertake an attempt to gain the integration for affixes’ chain. Roots still need such an integrative effort. At least, there is an empirical observation (made by V.Kromer in 2001) that length of a root is, on the average, twice as longer than that of a possible morpheme unit on the “zero” position in a morphemic chain, if this possible morpheme followed general tendency in length/positional dependence specific for all the rest morphemes (affixes). Is it so for words of various categories (grammatic, age, etc.) and why it is so – questions for further research.
Hopefully, all this can lead to the construction of quantitative theory of length dependences in Human Language including prediction for quantitative laws for the length distrbutions of units of varios linguistic levels.
References
Altmann, G.1980. Prolegomena to Menzerath's Law // Glottometrika 2. - Bochum: Brockmeyer. - Pp. 1-10.
Altmann, G., Schwibbe, M. H.1989. Das Menzerathsche Gesets in informationsverarbeitenden Systemen / Mit Beitragen von Werner Kaumanns, Reinchard Koehler und Joachim Wilde. - Hildesheim; Zurich; New-York: Georg Olms Verlag,. - 132 S.
Fenk, A. and Fenk-Oszlon, G. 1993. Menzerath's Law and the Constant Flow of Linguistic Information // Contributions to Quantitative Linguistics / Ed. By R. Koehler and B.B. Rieger. - Dordrecht; Boston; London: Kluwer Academic Publishers. - Pp. 11-32.
Gerlach, R.1982. Zur Ueberpruefung des Menzerath'schen Gesetzes im Bereich der Morphologie // Lehfeldt, W.; Strauss, U. (Hrsg.): Glottometrika4. - Bochum: Brockmeyer, 95-102.
Hřebнček,L. 1995. Text Levels. Language Constructs, Constituents and the Menzerath-Altmann Law. – Trier: Wissenschaftlicher Verlag, 1995. - 162 s.
Khmelev, D.V., Polikaprov A.A. 2000. Regularities of Sign's Life Cycle as a Basis for System Modeling of Human Language Evolution // Abstracts of papers for Qualico-2000. - Praha, 2000. (http://www.philol.msu.ru/~lex/khmelev/proceedings/qualico2000.html).
Koehler, R. 1986. Zur linguistischen Synergetik: Struktur und Dynamik der Lexik. - Bochum: Brockmeyer.
Koehler, R. 1989. Das Menzeratsche Gesetz als Resultatdes Sprachverarbeittungs-mechanismus // Altmann, G., Schwibbe, M. H. Das Menzerathsche Gesets in informationsverarbeitenden Systemen / Mit Beitragen von Werner Kaumanns, Reinchard Koehler und Joachim Wilde. - Hildesheim; Zurich; New-York: Georg Olms Verlag.
Menzerath, P.1954. Die Architektonik des deutchen Wortschatzes. - Bonn: Dummler.
Polikarpov A.A.1993. On the Model of Word Life Cycle // Koehler, R., Rieger, B. (eds.) Contributions to Quantitative Linguistics.- Dordrecht: Kluwer. - Pp. 53-66.
Polikaprov A.A.1998. Cyclic Processes in the Emergence of Lexical System: Modelling and Experiments. Doctoral Thesis. - Moscow (in Russian).
Polikaprov A.A.2000. Menzerath’s Law for Morphemic Structures of Words: A Hypothesis for the Evolutionary Mechanism of its Arising and its Testing // Abstracts of papers for Qualico-2000. - Praha, 2000.
Polikarpov A.A.2000a. Chronological Morphemic and Word-Formational Dictionary of Russian: Some System Regularities for Morphemic Structures and Units // Linguistische Arbeitsberichte. N 75. (Institut fuer Linguistik der Universitaet Leipzig). 3. Europaeische Konferenz “Formale Beschreibung Slavischer Sprachen, Leipzig 1999”. – Leipzig. - Pp. 201-212 ( http://www.philol.msu.ru/~lex/articles/fdsl.htm ).
Polikarpov A.A.2000b. Zakonomernosti obrazovanija novyh slov (Regularities of New Words Formation) // Jazyk. Glagol. Predlozhenie. Sbornik v chest' 70-letija G.G. Cil'nitskogo. - Smolensk. – Pp. 211 – 226. (in Russian) (http://www.philol.msu.ru/~lex/articles/words_ex.htm ) .
Polikaprov A.A.2001. Cognitive Foundations for Modelling Cyclic Processes in the Emergence of Lexical System // Trudy Kazanskoj shkoly po komp’juternoj i kognitivnoj lingvistike. TEL-2001. - Kazan’: Otechestvo http://www.philol.msu.ru/~lex/kogn/kogn_cont.htm .
Polikaprov A.A.2001a. Cognitive Model of Lexical System Evolution and its Verification // Site of the Laboratory for General and Computer Lexicology and Lexicography (Faculty of Philology, Lomonosov Moscow State University) http://www.philol.msu.ru/~lex/articles/cogn_ev.htm
Polikarpov A.A., Bogdanov V.V., Kryukova O.S. 1998. Chronological Morphemic-Word-formational Dictionary of Russian Language: Creation of a Database and its Systemic-Quantitative Analysis // Questions of General, Historical and Comparative Linguistics. Issue 2. - M.: Moskovskyi Litsey,. - p.172-184. (in Russian).