|
[An abstract of a paper for presenting at Qualico'2000 - Quantitative Linguistics Conference, Prague, 26-28 August 2000]
![]()
Menzerath’s Law for Morphemic Structures of Words:
A Hypothesis for the Evolutionary Mechanism of its Arising and its Testing
Anatoliy A. Polikarpov
Moscow Lomonosov State University, Faculty of Philology
Laboratory for General and Computational Lexicology and Lexicography
Karamzina 9-1-204 Moscow 117463 Russia
Fax: +7 (095) 939-31-78
e-mail: polikarp@philol.msu.ru
Key words: Menzerath’s Law, morphemic structures, language evolution
1. Aim of the Paper.
In the most general formulating Menzerath’s Law sounds like follows: the longer some " construct” (the whole) the shorter should be its “components” (parts) [Altmann, 1980; Altmann, Schwibbe, 1989]. In its historically initial form [Menzerath, 1954] it described the reverse proportional dependence of the average length of syllables in words on length of words (measured by number of contained in them syllables). Later on this law was expanded for describing regularities of various units on various levels of language organization (syntactic, textual, etc.) and even for describing other semiotic, bilogic, etc. phenomena). Nevertheless, it wasn’t theoretically founded and even wasn’t empirically studied on the basic sign level of any national variety of Human Language organization, level of morphemic units. Units of any other language levels (beginning from a word level) are formed mainly by combination of these basic units into more complex ones. That’s why quantitative-structural regularities for sign units of any other upper lying levels of language system can’t be independent on regularities happening on the basic, morphemic level, can’t be properly understood without theoretical and empirical study of regularities on it.
In this paper there is present (1) a hypothesis for understanding the evolutionary mechanism responsible for the Law arising and (2) some data for testing the hypothesis. For reaching the second goal the database “Chronological Morphemic and Word-Formational Dictionary of Russian Language” (CMWDRL) containing on the whole more than 180,000 words prepared at the Laboratory for General and Computer Lexicology and Lexicography at Moscow State Lomonosov University [Polikarpov, Bogdanov, Kryukova, 1998] is used. In this paper those results are present which concern analysis of only root and affixally derived Russian words (more than 50,000 different words).
2. A Hypothesis.
According to the model of sign life cycle [Polikarpov, 1993] it is natural to expect that the most probable (statistically dominant) direction for the categorial development within the nest of derivationally connected words will be the movement from some relatively concrete, objectively oriented categorial semantics of each word-base towards its derivatives of more abstract and subjectively oriented parts of speech categories. So, there should be a tendency to begin a word-formational tree mainly from nouns, to continue it step by step with adjectives, verbs, adverbs, pronouns, etc., and to end it with words of pure syntactic (functional) quality like conjunctions and prepositions.
This direction of the categorial development most basically is predetermined by the fundamental fact of the inescapable development of any word's integral lexical semantics during speech acts mainly into the direction of its greater abstractness. More abstract lexical semantics seeks corresponding more abstract categorial form (which is more organic to it) and finds it in acts of word-formation, producing further derivatives from previously derived words .
One of the most remarkable consequences of the mentioned process is probabilistic categorial, age, frequency and length ordering of morphemes within a wordform. It means that derivation affixes which are more distant to their root should be proportionally more grammatical, more frequent, and, finally, shorter than less distant ones. It is clear that just this phenomenon leads to the inescapable gradual diminishing of the average length of affixes and, correspondingly, of morphemes on the whole within longer wordforms, i.e. it leads to the existence of the law under study.
3. Data and Results.
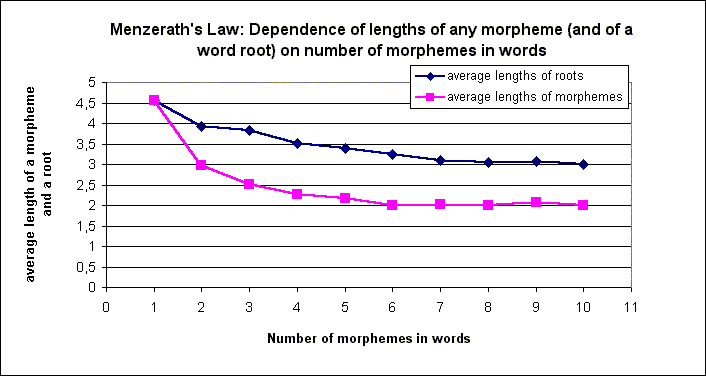
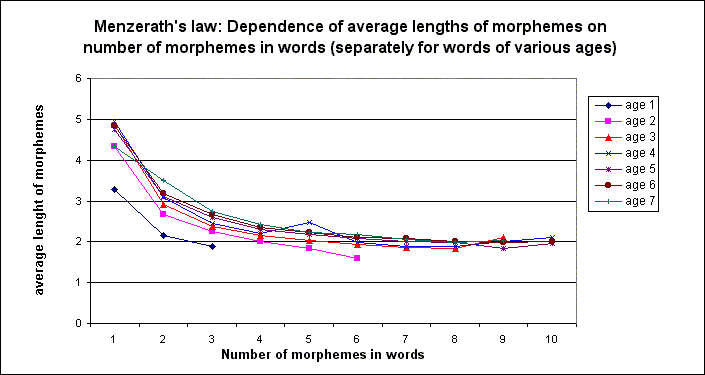
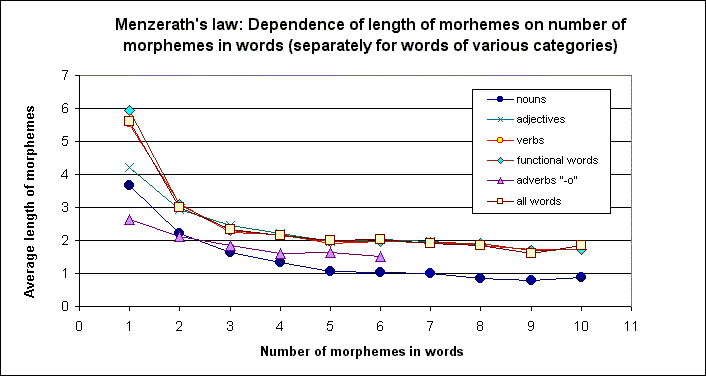
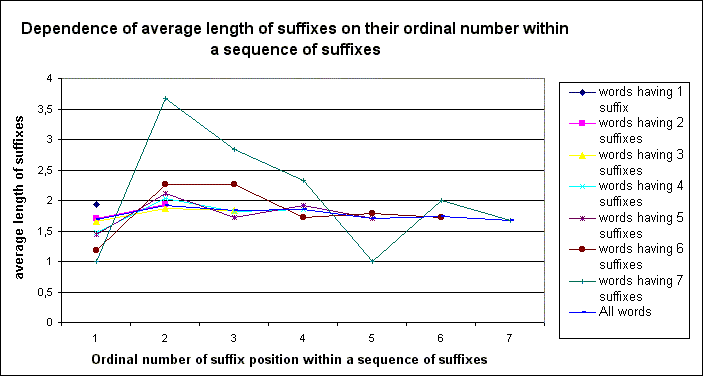
Below there is present some data on this point showing the validity of the derived general regularity and its significant variation for morphemic structures of words of various ages, categorial form, for roots of words as opposed to all morphemes together, and for suffixes in different positions within a word (figures 1-4).
3.1. By use of this data Menzerath’s Law in this study is certainly corroborated for morphemes of words of any part-of-speech category and words of any age. Words of different ages and categorial form demonstrate not only the astonishing analogy in following the law, but also the significant differences. For instance, words of the same length proportionally to the decline of their age (7 grades of ages - from the most ancient words of Indo-European and older origin, to gradually younger and younger words up to the youngest words of the 20th century) are built with the use of gradually longer morphemes. This, presumably, demonstrates that, on the average, younger and less grammatical words are built by younger morphemes.
3.2. A phenomenon of the average morphemes’ length reverse proportional dependence on the ordinal number of morphemes’ position within a word (i.e., the more distant a suffix from a root, the smaller is the length of a suffix), in our opinion, is of even more fundamental importance for the theory than a menzerathian itself. As a matter of fact, Menzerath’s law itself is a derivative of the more basic positional dependence of morphemes’ length on place and, therefore, function of morphemes in a word.
4. Oscillation Phenomenon.
While empirical data obtained from CMWDRL for the chains of suffixes of Russian words in general is in line with just proclaimed dependence there is also observed some slighter tendency for oscillations, i.e. rhythmically repeating and gradually diminishing “plus” and “minus” weak deviations from the main dependence stream. Some evolutionary explanation for it also will be present at the Conference.
Figures 1-4.
(click on small figures to see a real size of them)
References
Altmann, G. Prolegomena to Menzerath's Law//Glottmetrika 2. - Bochum: Brockmeyer, 1980. - Pp. 1-10
Altmann, G., Schwibbe, M. H. Das Menzerathsche Gesets in informationsverarbeitenden Systemen/Mit Beitragen von Werner Kaumanns, Reinchard Koehler und Joachim Wilde. - Hildesheim; Zurich; New-York: Georg Olms Verlag, 1989. - 132 S.
Chronological Morphemic and Word-Formational Dictionary of Russian Language (CMWDRL). Laboratory on General and Computational Linguistics, Faculty of Philology, Moscow Lomonosov University.
Menzerath, P. Die Architektonik des deutchen Wortschatzes. - Bonn: Dummler, 1954.
Polikarpov A.A., Bogdanov V.V., Kryukova O.S. Chronological Morphemic-Wordformational Dictionary of Russian Language: Creation of a Database and its Systemic-Quantitative Analysis// Questions of General, Historical and Comparative Linguistics. Issue 2. - M.: Moscovskyi Litsey, 1998 -p.172-184.
Polikarpov A.A. On the Model of Word Life Cycle // Koehler, R., Rieger, B. (eds.) Contributions to Quantitative Linguistics.- Dordrecht: Kluwer, 1993. - Pp. 53-66.